
 Star Trek TNGのRelicsを観ました。まあ何と言うかファンサービス回でしたね。TOSのスコッティが事故にあって、転送装置の途中状態で生き延びていて75年経ったEnterprise-Dに現れるという話。ダイソン・スフィアという良く分からない重力場があって、そこにかつて住民がいたのですが、惑星の機構自体が生き延びていて、エンタープライズ号は中に取り込まれてしまいます。という具合で結構SFしている話かと思いきや、結局はスコッティが長い経験を活かして知恵を出し、エンタープライズ号を救ったというだけのお話です。ホロデッキでTOSのコンソールが再現されるのがまあミソ。
Star Trek TNGのRelicsを観ました。まあ何と言うかファンサービス回でしたね。TOSのスコッティが事故にあって、転送装置の途中状態で生き延びていて75年経ったEnterprise-Dに現れるという話。ダイソン・スフィアという良く分からない重力場があって、そこにかつて住民がいたのですが、惑星の機構自体が生き延びていて、エンタープライズ号は中に取り込まれてしまいます。という具合で結構SFしている話かと思いきや、結局はスコッティが長い経験を活かして知恵を出し、エンタープライズ号を救ったというだけのお話です。ホロデッキでTOSのコンソールが再現されるのがまあミソ。
投稿者: kanrisha
無音のオノマトペ「しーん」
 この画像は、水木しげるの「ゲゲゲの鬼太郎」の中の「妖花」というエピソードのラストの部分で、非常に印象深いものです。この漫画について英語化してオンライン英会話のアメリカ人やイギリス人に見せようかと思いついたのですが、このコマの中で重要な「しーん」が良く考えたら英語には訳せません!以前海外のアニメファンが、「日本語には無音を表すオノマトペがある!」って言っていたのを思い出しました。私が思うには、これは中国語の「沈沈」(「夜沈沈」で夜が深深と更けていくこと)などから来たのかな、と思います。国語辞書では「深深」の表記ですが。
この画像は、水木しげるの「ゲゲゲの鬼太郎」の中の「妖花」というエピソードのラストの部分で、非常に印象深いものです。この漫画について英語化してオンライン英会話のアメリカ人やイギリス人に見せようかと思いついたのですが、このコマの中で重要な「しーん」が良く考えたら英語には訳せません!以前海外のアニメファンが、「日本語には無音を表すオノマトペがある!」って言っていたのを思い出しました。私が思うには、これは中国語の「沈沈」(「夜沈沈」で夜が深深と更けていくこと)などから来たのかな、と思います。国語辞書では「深深」の表記ですが。
NHK杯戦囲碁 西健伸6段 対 張豊猷9段(2026年7月5日放送分)
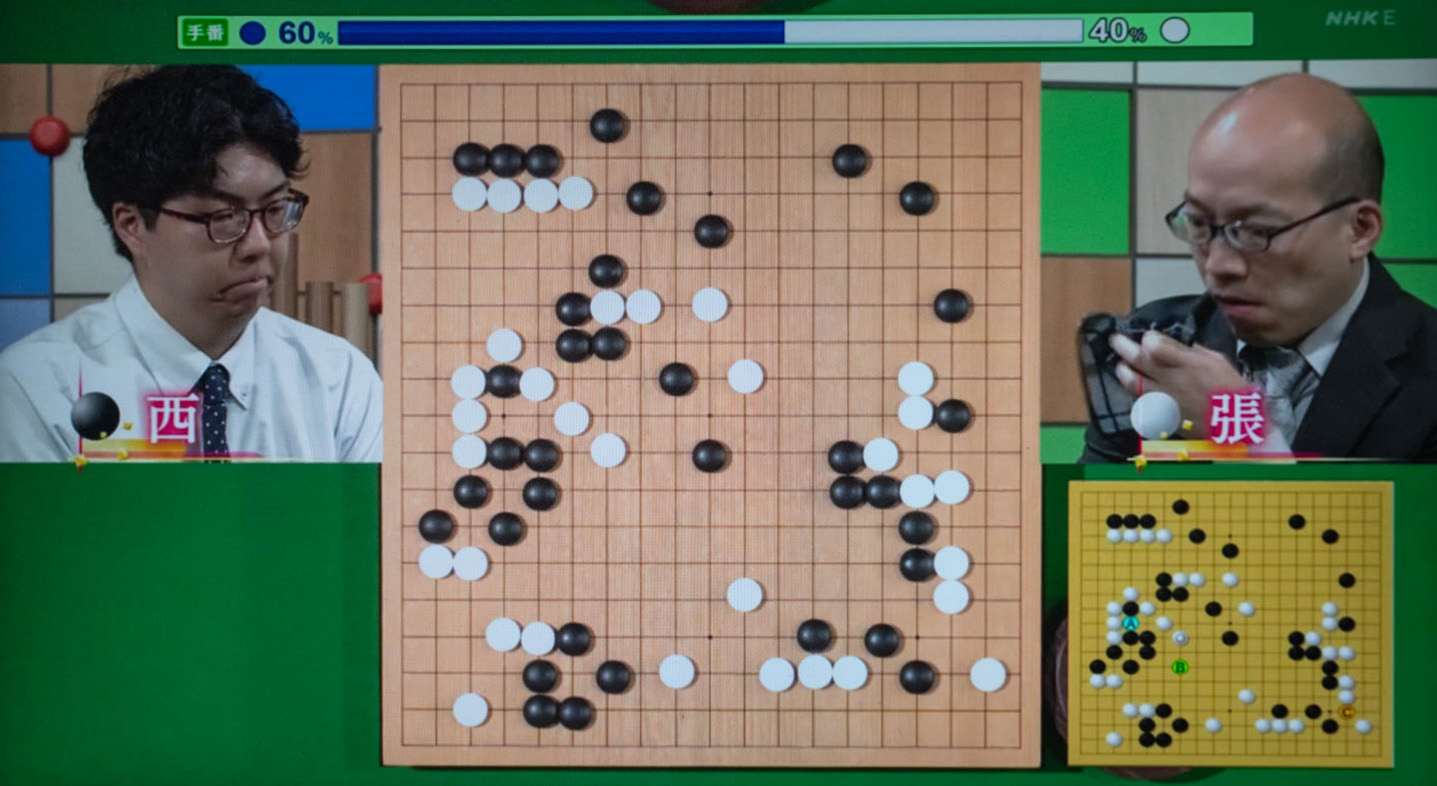
本日のNHK杯戦囲碁は、黒番が西健伸6段、白番が張豊猷9段の対局でした。この碁は両者が力を出し合った戦いに終始した碁となりました。特に白が右下隅から延びる黒石を攻めた時、黒が白の右辺の一部を破ってここが大きな劫になりました。この劫の出入りが50目レベルという大きな劫で、白が左辺に劫立てしたのに黒は受けてはいられず劫を解消しました。こうなると左辺の黒がそのまま取られているのかどうかが焦点になり、黒は動き出しましたが手にならず、結局そこの折衝から派生して中央がお互いに切り合った形になり、これまた大型の攻め合いになりました。しかし黒は1~2手ぐらい手数が短く、黒が投了しました。
Doctor WhoのDoctor Who and the Silurians (エピソード1)
 Doctor WhoのDoctor Who and the Siluriansのエピソード1を観ました。今回の舞台はあるサイクロトロン施設が洞窟群の中に作られたのですが、その洞窟の中で作業した者が次々に死んだり、精神的におかしくなったりという事故が続出し、UNITが呼ばれます。ドクターはその犠牲者の一人が病院の壁に何かの絵を描き続けるのを見て、洞窟に何かあると単身乗り込みますが、そこに人間サイズの恐竜が出現し、というところでまた来週。例によってDoctor Whoは最初の方はかったるいです。
Doctor WhoのDoctor Who and the Siluriansのエピソード1を観ました。今回の舞台はあるサイクロトロン施設が洞窟群の中に作られたのですが、その洞窟の中で作業した者が次々に死んだり、精神的におかしくなったりという事故が続出し、UNITが呼ばれます。ドクターはその犠牲者の一人が病院の壁に何かの絵を描き続けるのを見て、洞窟に何かあると単身乗り込みますが、そこに人間サイズの恐竜が出現し、というところでまた来週。例によってDoctor Whoは最初の方はかったるいです。
サンダーバードの Sun Probe
 サンダーバードの Sun Probe観ました。普段、基地と5号の間の輸送にしか使われない3号が、太陽調査のロケットを救助に大活躍。なんですがそのロケットを救助した後、今度は3号が太陽に向かってまっしぐら、で乗っていたスコット、アラン、ティンティンの3人が暑さで気絶します。それを救ったのがヒマラヤ山脈の中からロケットに向けて信号を送ろうとしていた2号で、ヴァージルとブレインズが、そこから3号にアクセスして軌道を変えようとします。しかしブレインズがコンピューターを積み忘れ、その代わりにブレインズが開発したチェス用ロボットのブレイマンが入っていました。しかしその電子頭脳に何とか周波数を計算させて、危機一髪OKという話。しかしその計算、単に通信用周波数の計算でせいぜいドップラー効果でずれる分の補正くらいで、その当時なら計算尺でも出来たと思います。まあ、写真見てもらうと分かりますが、普段3号は宇宙を飛んでいるシーンばかりなので小型に見えますが、実際には1号の倍以上あります。まあ往復型宇宙ロケットですから、当たり前ですが。しかし、宇宙なのに宇宙服なしでのミッションもあり得ないと思いますが。(笑)
サンダーバードの Sun Probe観ました。普段、基地と5号の間の輸送にしか使われない3号が、太陽調査のロケットを救助に大活躍。なんですがそのロケットを救助した後、今度は3号が太陽に向かってまっしぐら、で乗っていたスコット、アラン、ティンティンの3人が暑さで気絶します。それを救ったのがヒマラヤ山脈の中からロケットに向けて信号を送ろうとしていた2号で、ヴァージルとブレインズが、そこから3号にアクセスして軌道を変えようとします。しかしブレインズがコンピューターを積み忘れ、その代わりにブレインズが開発したチェス用ロボットのブレイマンが入っていました。しかしその電子頭脳に何とか周波数を計算させて、危機一髪OKという話。しかしその計算、単に通信用周波数の計算でせいぜいドップラー効果でずれる分の補正くらいで、その当時なら計算尺でも出来たと思います。まあ、写真見てもらうと分かりますが、普段3号は宇宙を飛んでいるシーンばかりなので小型に見えますが、実際には1号の倍以上あります。まあ往復型宇宙ロケットですから、当たり前ですが。しかし、宇宙なのに宇宙服なしでのミッションもあり得ないと思いますが。(笑)
Doctor WhoのSpearhead from the Sky エピソード4
 Doctor Whoでシーズン3のSpearhead from the Sky に戻ってエピソード4を観ました。これまでダラダラと引っ張って来ましたが、ようやく話の本質が分かって、ネスティーンというエイリアンが地球を植民星にしようとして、マネキン工場を乗っ取って、政治家などのVIPをリモコンで動くマネキン人形に置き換え、またショーウィンドーのマネキン人形を各地で警察を襲わさせたりして、ということで地球征服を企みます。面白いのはUNITの上司もマネキン人形に置き換えられてしまうことです。ドクターは何やら真空管で怪しげな発振装置みたいなのを開発し、それでマネキン人形を倒し、最後はマネキン人形を操っている宇宙から来た脳みたいなのを倒して、ようやくマネキン人形全滅、という話です。どうやらシーズン3のドクターは、比較的科学者的キャラのようです。
Doctor Whoでシーズン3のSpearhead from the Sky に戻ってエピソード4を観ました。これまでダラダラと引っ張って来ましたが、ようやく話の本質が分かって、ネスティーンというエイリアンが地球を植民星にしようとして、マネキン工場を乗っ取って、政治家などのVIPをリモコンで動くマネキン人形に置き換え、またショーウィンドーのマネキン人形を各地で警察を襲わさせたりして、ということで地球征服を企みます。面白いのはUNITの上司もマネキン人形に置き換えられてしまうことです。ドクターは何やら真空管で怪しげな発振装置みたいなのを開発し、それでマネキン人形を倒し、最後はマネキン人形を操っている宇宙から来た脳みたいなのを倒して、ようやくマネキン人形全滅、という話です。どうやらシーズン3のドクターは、比較的科学者的キャラのようです。
フリーになりました。
先月6月26日で65歳になって、今の会社での正社員として働くのは終了し、今日からフリーで業務委託契約ベースで働くことになります。契約は1年単位で、いつまで続けられるかは分かりません。ただ往復4時間の通勤が完全に無くなったのは大きいです。健康保険(任意継続)の手続き、年金の手続き、そして所得税支払いのための青色申告の開始届など、取り敢えず色々と書類を作って出す必要があります。
アルバート・テルーン後日談
20年以上前の話ですが、紀田順一郎さんが子供の時に犬に襲われ、その時に少年倶楽部で読んだ撃退法を試したら効果覿面で、その出元の「アルバート・テルーン」って誰なんだろう、とHPに書かれていたのを私が読んで、色々検索して「名犬ラッド」の作者であるアルバート・ペイスン・ターヒューンであることを突き止め、紀田さんにメールで教えてあげたことがあります。
https://shochian2.com/archives/34050
最近このブログ記事にコメントをいただいて、その話が紀田さんの「横浜少年物語」に出ていることを教えてもらって取り寄せてみました。さすが作家らしく結構脚色されていました。会社で紀田さんに教えてもらったのではないですし、また検索タームもAlbert Dogではなく、それらしい綴りを色々試していたらGoogleのSuggestionで出てきたというのが真相です。(笑)
ちなみに、アルバート・ターヒューンのこの犬の防護法自体は効果があるものの、万一犬に嚙まれた時の処置についてはターヒューンは結構アバウトなことを言っていて、専門家に批判されていました。
スタートレック・TNGのMan of the People
 スタートレック・TNGのMan of the Peopleを観ました。このエピソードもパターン化されたディアナ・トロイの受難話で、トロイってエンパスで相手の感情が分かるという設定なので、そこをつけこまれてエイリアン他に利用される回が本当に多いんですが、今回もまさにそれ。ある外交官が、外交官として交渉を上手くまとめるために、自分のネガティブな感情や老化の要素をある女性に送り込む、というめちゃくちゃな設定で、それでトロイが被害に遭うもの。まあ見所は普段大人しめのトロイお姉さんがケバくなって、若い男を自室に引き込んだりしたりするシーン。単に脚本家がトロイにそういう演技をさせたかっただけでは、と思います。
スタートレック・TNGのMan of the Peopleを観ました。このエピソードもパターン化されたディアナ・トロイの受難話で、トロイってエンパスで相手の感情が分かるという設定なので、そこをつけこまれてエイリアン他に利用される回が本当に多いんですが、今回もまさにそれ。ある外交官が、外交官として交渉を上手くまとめるために、自分のネガティブな感情や老化の要素をある女性に送り込む、というめちゃくちゃな設定で、それでトロイが被害に遭うもの。まあ見所は普段大人しめのトロイお姉さんがケバくなって、若い男を自室に引き込んだりしたりするシーン。単に脚本家がトロイにそういう演技をさせたかっただけでは、と思います。
NHK杯戦囲碁 富士田明彦8段 対 平田智也8段(2026年6月28日放送分)
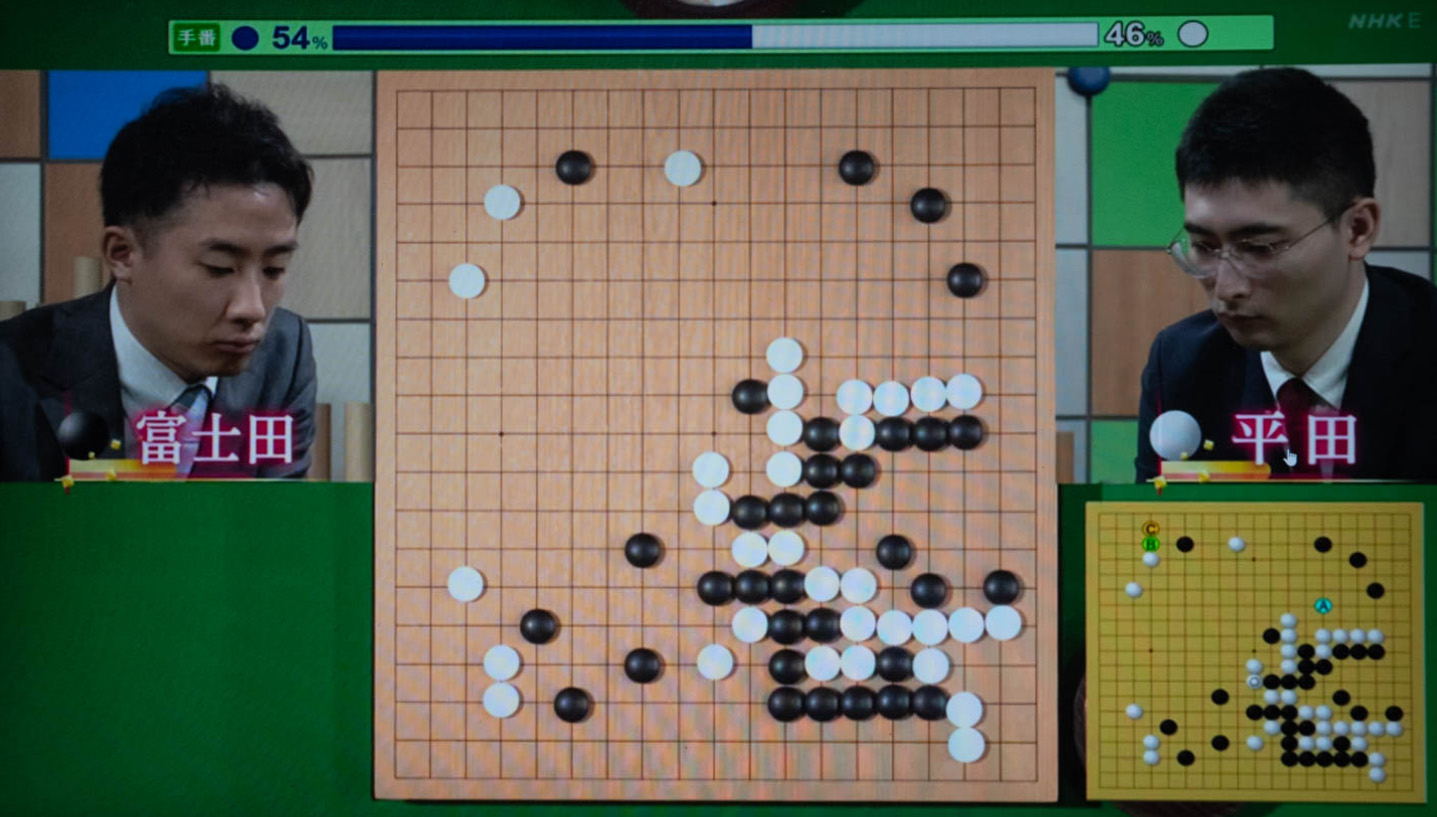
本日のNHK杯戦囲碁は黒番が富士田明彦8段、白番が平田智也8段の、実力伯仲の好対局となりました。序盤で黑が右下隅で、小目から大々ゲイマで5線に開くという奇手?を見せました。ただ結果的には後の打ち方でこの石は切り離されてしまったので、効果的とは言い難いように思います。その右辺の攻防が結構激しくなり、白も中央が切り離され、黒も右辺が活きていないという攻防になりました。しかしこの碁の勝敗のポイントは更に局面が進んで白が右上隅の黒地に手を付けていったところで、しかし白の侵入はちょっと遅かった感じで、上辺の黒の下がりが結構厚くて手になりませんでした。白は一転して右辺の黒を攻めましたが、この黒もそれほど寄りつかれずに活きて、これで黒が優勢になりました。結果として黒の5目半勝ちでした。